Suppose we have a list of random numbers, drawing from a uniform distribution ranging from .
Now, we sort the list so that they are in ascending order, and then calculate the differences between each consecutive pair. For example, suppose we have a list like:
The differences are
And then, we plot a histogram to see the frequency of each number. Here is 3000 output from a uniform integer distribution ranging from .
The distribution (except the first few bins) follows an exponential distribution of
In the above plot, the blue curve is
as the number of data is , and the range of the uniformdistribution is .
The problem is, why??
even normal distribution give exponential decay distribution of ordered difference!!
[20220211] update.
I understand why.
Suppose -random draws from discrete output from . For a give period , the mean number of count should be . Thus, using Poisson distribution, the probability of having -events inside this period is
Now, this is the tricky part, if we want to find difference of x between the consecutive events, that mean, . i.e. no event inside this period.
Why? This is because our question is if we have an event at a given time, How long do we have to wait to have the next event? What is the probability for a waiting period of to get the next event?
Therefore, there must be NO event within -period, so . And an event at the next immediate time. Thus,
In this post, we talked about the probability Limit of a null experiment. The simplest case is that, tossing a coin n-times, given r-head, what is the probability of have a fair coin? The straight answer is using the likelihood function of the coin has probability of given head.
Note that the area of the Likelihood function is not equal to 1.
So, the probability that the coin gives probability between to of head is
The meaning of 90% confident interval of the coin gives -probability of head is that,
using the above condition, the is the lower limit and is the higher limit.
For example, 10-toss, 8 heads.
The coin gives head 80% with lower limit of 63% and higher limit of 100%, for 90% confident interval.
And the likelihood of have a fair coin is
In the above example, there are 2 outputs. Now, we have a numbers to draw. How to formulate to check is the drawing mechanism is fair?
To simplify the study, let say . The likelihood of -draw, have counts and probability for each output is
But that is kind of complicated for more and more output.
Now, following similar idea, to determine whether a peak in a spectrum is real or not. We first determine the background level under the peak. the background should follow Poisson distribution. And we calculate the probability of have that count at the peak position.
Take the spectrum like this:
We estimate the background from bin 1 to 25, give mean value of 3.92. The likelihood function for background is
And we can see that, the probability for this background to produce the peak at 30 is very very small.
We can have a null hypothesis that there is no peak is the histogram, so, it is a uniform distribution. Now, we denote each bin from 1 to k. And add those output. then do a hypothesis testing that can we reject the null hypothesis of no structure.
For example, we have a spectrum like below. This one-tail probability is 3%. So, we can reject the null hypothesis.
The method only has a flaw is that, if the data size is way smaller than the number of outcome, this method will always reject the null hypothesis. And also, event the null hypothesis is rejected, we can only know there is a structure, not it does not tell where the structure is. The other things is, because it is base on a sum of data, so it is not sensitive to local structure. It only give a overview of the data.
I think, we can have a null hypothesis that there is a peak at 30. and formulate the null hypothesis probability.
Suppose a random variable with the probability distribution, and the parameter set of the distribution is , such that
What is the sum of these two distribution?
in the discrete case, it is
for continuous distribution is
$latex
Why convolution? Imagine we have a 2-D distribution on the and axis, such that , we want to project the distribution at the diagonal axis , so, we rotate the axis, so that , where . And integrate the area, we get the distribution for x+y. There is no intrinsic different between the continues and discrete cases.
Now, We give the general formula for add n-times of a discrete uniform distribution, ranging from {0, k}, and the relation between the Gaussian distribution. The uniform distribution is
The mean is easy to calculate. The mean of the sum of the squares from 1 to k . The square of mean is . So, the variance is . see this for algebra of distribution.
This distribution can help us to answer a questions. Is a coin fair? Say, a coin is tolled 10 times and got 8 heads. We denote head is 1, tail is 2. So, we have a score . The one-tail probability is 2.9%. So, for 95% confident level, we can reject that the coin is fair.
There are many good materials on Bayes theorem. I am here to give a little bit detail.
The Bayesian theorem states that:
for hypothesis being true. for evidence.
The above equation can be visualized using a Venn diagram:
The red box is the events , outside is not or . The green boxes is the events , outside the green boxes are not . It is obvious that
One common application is medical test. Given a test for a disease is 90% for true positive, and 10% for false positive. And the chance for having the disease among the population is 0.1%. What is the probability that a positive test really means infection?
From the data, we have , than
which is only 0.9% that he is infected. Let’s do another test, and it is still positive, than
which is still 7.6% that he is infected.
Number of test positive
1
0.89%
2
7.5%
3
42.2%
4
86.8%
5
98.3%
6
99.8%
This table shows that, for a very rare disease, 90% true positive testing method is not sufficient.
In fact, for ,
when ,
The above plot is the curve for as a function of for various . The black arrows started with prior , and they show that each positive test with will iterate toward higher and higher .
We can see that, if , the test is basically useless as that more false positive than true positive.
A more tricky thing is, what if, the 1st test is positive, the 2nd test is negative, and 3rd test is positive? In this case, we have to evaluate
Using the Venn diagram,
Using ,
So that the curve is the diagonal “mirror”.
The above plot start with prior . First test gives positive, the , but the 2nd test is negative, that gives . Back to the prior.
In above discussion, we assumed that , which is sum of the probabilities of the true positive and false positive are unity. But that is not necessary true.
If we simplify with simple variables, we have
where represents the for , and represents the other way. And we can check that
So, the curve for is same as with a transformation.
Up to today, there are zero covid reported for consecutive 40 days in Hong Kong. What is the probability that the virus is still exist in Hong Kong?
Our prior for the covid is , 20% of people has covid at ay 0-th. Assuming the probability that people with covid will show symptopes is 80%, and 20% will not show any symptoms. i.e . An also, it it is very likely that people without covid shows covid symptopes, i.e. . And we also suppose that the covid testing had 70% true positive and 10% false positive.
The probability for reporting a covid case is the sum of tested positive with symptopes, plus false positive with fake symptopes.
, so, there is 56% chance that a true covid will be reported.
, there is 8% chance that a false covid will be reported.
so, , there is 17.6% chance that a covid will be reported in the population.
, thus, there is 11% chance that there is a covid but no case reported on the 1st day.
Here is the plot for the vs number of day of zero report case.
Hong Kong has 7.5 million people, at 20th days of zero case reported, there could be 1 people infected and hidden in the population. But at 40th days of zero case reporte, the chance to have covid is .
In the early days of the pandemic policy, the HK gov required 21 days with no case reported as a condition for relaxing the measure, which is reasonable. As in our rough estimation, there still could be 1 real case among the population.
In our rough estimation, we ignored the spreading of the covid. To include the covid spreading, we can multiple the R-factor to the everyday. Suppose the R-factor is 0.7, the actual covid case in the population for the 1st day of zero-case reported will be and so on. It turns out, needs more time to as small as . But
Given Hong Kong is one of the lowest infection rate among the world, the effective R-factor should be small or close to 0. R=0.7 is like without any protection.
In this post, we discussed the Goodness of Fit for a simple regression problem.
In nuclear physics, the data we collected are plotted in histogram, and we have to fit the histogram to find the energies and resolutions. This is another class of problem for Goodness of Fit.
In general, depends on how we treat the data,
treat it as a regression problem with error for each data follows Poisson distribution.
treat it as a testing hypothesis that what is the chance for the experimental distribution be observed, given that the model distribution is truth?
For the regression problem, there are 2 mains metrics, one is the R-squared, and the another is the chi-squared.
For the testing hypothesis, the experimental data is tested against the null hypothesis, which is the model distribution. A common method is the Pearson’s chi-squared test.
Note that the chi-squared and chi-squared test are two different things, although they are very similar in the algorithm.
Another note is that, please keep in mind that there are many things not discussed in below, there are many details and assumptions behind.
The R-squared is very simple, the meaning is How good the model captures the data. In a standard ANOVA (Analysis of variance, can be imagine as the partition of the SSTotal ), we have
The SSRTotal is the sum of square of “residuals” against the mean value. i.e., If the data has no feature, no peak, the SSTotal will be minimum. SSTotal represents the “size” of the feature in the data. Larger the SSTotal, the data is more different from the mean values, and more feature-rich.
The SSR is the sum of square of residuals against the fitted function. If the model captures the data very well, SSR will be minimum. Since the data could have some natural fluctuation, the represents the unbiased estimator of the “sample variance”, where is the number of degree of freedom.
is the size of the data, is the number of parameter of the model, or the size of the model. The SSTotal is the “size” of feature, SSR is the “size” of the things that did not captured by the model. The basic of ANOVA is the study of the partition of the data.
The difference between SSTotal and SSR is the “size” of the model captured data.
The idea of R-squared is that, the numerator is the size that the model captured from the data, and the denominator is the size of the feature in the data. If the data is featureless, thus the data is mainly from the natural fluctuation, therefore, there is nothing a model can be captured. so, R-squared will be small.
Chi-squared includes the sample variance,
We can see that the is (roughly) the SSR divided by sample variance . As we discussed before, the SSR is the size of the natural fluctuation — sample variance. If we divided the SSR with the sample variance, the when the fitting is good. It is because, if the fitting is not good, the SSR will be larger than the sample variance (as there are something the model did not capture), or, if the fitting is too good, the SSR will be much smaller than the sample variance.
For histogram data, the sample variance of each bin should follow the Poisson statistics that .
The reduced chi-squared is
For data points, they are living in the “n-dimensional” space. Suppose there is a model to generate these data points, and the model has parameters. Thus, the model “occupied” “p-dimensional” space. The rest “(n-p)-dimensional” space is generated by the natural fluctuation. Thus, the “size” of the should be (n-p) or the degree of freedom. For a good fit
Pearson’s chi-squared test, is a testing, asking, does the data distribution can be captured by a model distribution, more technically, what is the probability to observed the experimental distribution, given that the model distribution is truth. One limitation for using this test is that, the number of data for each bin cannot be too small.
The test calculate the following quantity,
The follows the -distribution with degree of freedom .
As all testing hypothesis, we need to know the probability of the tail. For -distribution, only 1-tail is available, and this is usually called the p-value. Here shows an example of the -distribution.
The meaning of the p-value is that,
given the null hypothesis, or the model distribution, is truth, the probability of the experimental data happen.
When the p-value is less than 5%, the null hypothesis should be rejected. In other word, the model distribution cannot represents the experimental distribution. Or, if the model distribution is truth, less than 5% chance to observe the experimental data.
Suppose we have a prior probability , and we have a observation from the prior probability that the likelihood is , thus, according to the Bayesian probability theory, the updated, posterior probability is
Here, are called conjugate distribution. is called conjugate prior to the likelihood .
suppose we have no knowledge on the prior probability, it is a fair assumption that or uniform, then, the posterior probability is proportional to the likelihood function, i.e.
.
Now, suppose we know the prior probability, after updated with new information, if the prior probability is “stable”, the new (or posterior) probability should have the similar functional form as the odd (prior) probability!
When the likelihood function is Binomial distribution, it is found that the beta distribution is the “eigen” distribution that is unchanged after update.
where is the beta function, which served as the normalization factor.
After success trails and failure trial, the posterior is
When , the posterior probability is reduced to binomial distribution and equal to the Likelihood function.
It is interesting to write the Bayesian equation in a “complete” form
Unfortunately, the beta distribution is undefined for , therefore, when no “prior” trials was taken, there is no “eigen” probability.
Suppose we want to measure the probability of tail of a coin. And found that after 100 toss, no tail is appear, with is the upper limit of the probability of tail?
Suppose we have a coin, we toss it for 1 time, it show head, obviously, we cannot say the coin is biased or not, because the probability base on the result has not much information. So, we toss it 2 times, it shows head again, and if we toss it 10 time, it shows 10 heads. So, we are quite confident that the coin is biased to head, but how biased it is?
Or, we ask, what is the likelihood of the probability of head?
The probability of having head in toss, given that the probability of head is is
Now, we want to find out the “inverse”
This will generate a likelihood function.
The peak position of the likelihood function for binomial distribution is
Since the distribution has a width, we can estimate the width by a given confident level.
From the graph, more the toss, the smaller of the width, and narrower of the uncertainly of the probability.
As the binomial distribution approach normal distribution when .
where and .
When , no head was shown in toss, the likelihood function is
The Full-width Half-maximum is
We can assign this is a “rough” the upper limit for the probability of head.
Testing hypothesis may be the most used and most misunderstood statistics tool. When we do even a simple fitting, and want to evaluate the fitting result, we have to use the hypothesis testing. One common quantity used is the reduced chi-squared.
A hypothesis testing means given an observation and hypothesis, Is the hypothesis NOT true? right, hypothesis test never tell us the trueness of the hypothesis, but the wrongness of it. The core of the test is “Can werejectthe null hypothesis?”
There are one-tailed and two-tailed testing, as a result, the p-value has different meanings.
The p-value is the probability that the model agree with the observation. when the p-value too small, smaller than the confident level, the null hypothesis Rejected. But if the p-value is very large, in a 1-tailed test, we cannot say the null hypothesis is true, but we can say the null hypothesis CANNOT be rejected.
In 2-tailed test, there are two p-values, corresponding to each tail.
First of all, the variance of a distribution is not equal its sigma, except for Normal distribution.
In an observation, there should be an intrinsic variance, for example, some hole size, or physical windows. And there is a resolution from the detection. As a result, we observed an overall effect of the intrinsic variance and the detector resolution. In an data analysis, one of the goal is the find out the resolution.
Lets denote the random variable of the intrinsic variance is
and the resolution of the detection is an other random variable of Normal distribution,
Then, we observed,
,
according to the algebra of distribution.
If the and the the intrinsic distribution is NOT a gaussian, say, it is a uniform distribution, then, the observed distribution is NOT a gaussian. One why to get the resolution is to do de-convolution. Since we are not interesting on the intrinsic distribution but the resolution, thus we can simply use the variance of the intrinsic distribution and the variance of the observed distribution to extract the resolution.
When , the observed distribution is mostly a gaussian-like. and we can approximate the observed variance as the squared-sigma of a gaussian fit.
for example, in deducing the time resolution using time-difference method with a help of a tracking, that a narrow width of the position was gated.
The narrow width of the position is equivalent to a uniform distribution of time-difference. Thus, the time resolution is deduced using the observed variance and the variance of the uniform distribution. For the width of the position is , the width of the time difference is
,
Thus,
The variance of an uniform distribution is 1/12 of the square of the width.
The effect of the factor 1/12 is very serious when the resolution is similar with the width of the time difference. But can be neglected when .
Because of missing this 1/12 factor, the resolution will be smaller than actual resolution.
Here is an example, I generated 10,000 data, the intrinsic distribution is a uniform distribution from 0 to 100, the resolution is a gaussian of sigma of 20. The result distribution is a convolution of them.
When find resolution using projection from a 2-D distribution, we should be careful about the projected 1-D distribution and its variance. For example, a uniform 2-D disk projected to 1-D distribution, the 1-D distribution is not uniform but a half circle,
the variance is .
the formula to calculate variance is
,
where is the pdf.
ToDo, estimate the error of the deduced resolution, with number of data. For small number of data, the error should be large. but how large?
We assumed each data point is taking from a distribution with mean and variance
in which, the mean can be a function of X.
For example, we have a data , it has relation with an independent variable . We would like to know the relationship between and , so we fit a function .
After the fitting (least square method), we will have so residual for each of the data
This residual should be follow the distribution
The goodness of fit, is a measure, to see the distribution of the residual, agree with the experimental error of each point, i.e.
Thus, we would like to divide the residual with and define the chi-squared
.
we can see, the distribution of
and the sum of this distribution would be the chi-squared distribution. It has a mean of the degree of freedom . Note that the mean and the peak of the chi-squared distribution is not the same that the peak at .
In the case we don’t know the error, then, the sample variance of the residual is out best estimator of the true variance. The unbiased sample variance is
,
where is degree of freedom. In the cause of , the , because there is 1 degree o freedom used in x. And because the 1 with the b is fixed, it provides no degree of freedom.
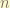













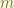







 to
to  of head is
of head is
 -probability of head is that,
-probability of head is that, 


 numbers to draw. How to formulate to check is the drawing mechanism is fair?
numbers to draw. How to formulate to check is the drawing mechanism is fair?  . The likelihood of
. The likelihood of  counts and probability
counts and probability  for each output is
for each output is



 , such that
, such that 


 axis, such that
axis, such that  , we want to project the distribution at the diagonal axis
, we want to project the distribution at the diagonal axis  , so, we rotate the axis, so that
, so, we rotate the axis, so that  , where
, where  . And integrate the area, we get the distribution for x+y. There is no intrinsic different between the continues and discrete cases.
. And integrate the area, we get the distribution for x+y. There is no intrinsic different between the continues and discrete cases. 


 . The square of mean is
. The square of mean is  . So, the variance is
. So, the variance is  .
.  . The one-tail probability is 2.9%. So, for 95% confident level, we can reject that the coin is fair.
. The one-tail probability is 2.9%. So, for 95% confident level, we can reject that the coin is fair. 

 for hypothesis being true.
for hypothesis being true.  for evidence.
for evidence. 
 . The green boxes is the events
. The green boxes is the events  , outside the green boxes are not
, outside the green boxes are not 


 , than
, than


 ,
, 
 ,
, 

 for various
for various  . The black arrows started with prior
. The black arrows started with prior  , and they show that each positive test with
, and they show that each positive test with  will iterate toward higher and higher
will iterate toward higher and higher  , the test is basically useless as
, the test is basically useless as  that more false positive than true positive.
that more false positive than true positive. 


 ,
, ![\displaystyle P(H|\hat{E}) [P(E|H)] = P(H|E) [1-P(E|H)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%28H%7C%5Chat%7BE%7D%29+%5BP%28E%7CH%29%5D+%3D+P%28H%7CE%29+%5B1-P%28E%7CH%29%5D+&bg=fafad3&fg=6f5e4e&s=0&c=20201002)

 . First test gives positive, the
. First test gives positive, the  , but the 2nd test is negative, that gives
, but the 2nd test is negative, that gives  . Back to the prior.
. Back to the prior.  , which is sum of the probabilities of the true positive and false positive are unity. But that is not necessary true.
, which is sum of the probabilities of the true positive and false positive are unity. But that is not necessary true.


 represents the
represents the  for
for  , and
, and  represents the other way. And we can check that
represents the other way. And we can check that 
 with a transformation.
with a transformation.  , 20% of people has covid at ay 0-th. Assuming the probability that people with covid will show symptopes is 80%, and 20% will not show any symptoms. i.e
, 20% of people has covid at ay 0-th. Assuming the probability that people with covid will show symptopes is 80%, and 20% will not show any symptoms. i.e  . An also, it it is very likely that people without covid shows covid symptopes, i.e.
. An also, it it is very likely that people without covid shows covid symptopes, i.e.  . And we also suppose that the covid testing had 70% true positive and 10% false positive.
. And we also suppose that the covid testing had 70% true positive and 10% false positive. 
 , so, there is 56% chance that a true covid will be reported.
, so, there is 56% chance that a true covid will be reported.  , there is 8% chance that a false covid will be reported.
, there is 8% chance that a false covid will be reported.  , there is 17.6% chance that a covid will be reported in the population.
, there is 17.6% chance that a covid will be reported in the population. , thus, there is 11% chance that there is a covid but no case reported on the 1st day.
, thus, there is 11% chance that there is a covid but no case reported on the 1st day.  vs number of day of zero report case.
vs number of day of zero report case. 
 .
.  and so on. It turns out,
and so on. It turns out,  . But
. But 


 represents the unbiased estimator of the “sample variance”, where
represents the unbiased estimator of the “sample variance”, where  is the number of degree of freedom.
is the number of degree of freedom.


 is (roughly) the SSR divided by sample variance
is (roughly) the SSR divided by sample variance  . As we discussed before, the SSR is the size of the natural fluctuation — sample variance. If we divided the SSR with the sample variance, the
. As we discussed before, the SSR is the size of the natural fluctuation — sample variance. If we divided the SSR with the sample variance, the  when the fitting is good. It is because, if the fitting is not good, the SSR will be larger than the sample variance (as there are something the model did not capture), or, if the fitting is too good, the SSR will be much smaller than the sample variance.
when the fitting is good. It is because, if the fitting is not good, the SSR will be larger than the sample variance (as there are something the model did not capture), or, if the fitting is too good, the SSR will be much smaller than the sample variance.  .
. 
 parameters. Thus, the model “occupied” “p-dimensional” space. The rest “(n-p)-dimensional” space is generated by the natural fluctuation. Thus, the “size” of the
parameters. Thus, the model “occupied” “p-dimensional” space. The rest “(n-p)-dimensional” space is generated by the natural fluctuation. Thus, the “size” of the  should be (n-p) or the degree of freedom. For a good fit
should be (n-p) or the degree of freedom. For a good fit

 follows the
follows the 
 , and we have a observation from the prior probability that the likelihood is
, and we have a observation from the prior probability that the likelihood is  , thus, according to the Bayesian probability theory, the updated, posterior probability is
, thus, according to the Bayesian probability theory, the updated, posterior probability is
 are called conjugate distribution.
are called conjugate distribution.  is called
is called  .
. or uniform, then, the posterior probability is proportional to the likelihood function, i.e.
or uniform, then, the posterior probability is proportional to the likelihood function, i.e. .
.
 is the beta function, which served as the normalization factor.
is the beta function, which served as the normalization factor. success trails and
success trails and  failure trial,
failure trial, 
 , the posterior probability is reduced to binomial distribution and equal to the Likelihood function.
, the posterior probability is reduced to binomial distribution and equal to the Likelihood function.
 , therefore, when no “prior” trials was taken, there is no “eigen” probability.
, therefore, when no “prior” trials was taken, there is no “eigen” probability.




 .
.
 and
and  .
. , no head was shown in
, no head was shown in 




 ,
, and the the intrinsic distribution is NOT a gaussian, say, it is a uniform distribution, then, the observed distribution is NOT a gaussian. One why to get the resolution is to do de-convolution. Since we are not interesting on the intrinsic distribution but the resolution, thus we can simply use the variance of the intrinsic distribution and the variance of the observed distribution to extract the resolution.
and the the intrinsic distribution is NOT a gaussian, say, it is a uniform distribution, then, the observed distribution is NOT a gaussian. One why to get the resolution is to do de-convolution. Since we are not interesting on the intrinsic distribution but the resolution, thus we can simply use the variance of the intrinsic distribution and the variance of the observed distribution to extract the resolution. , the observed distribution is mostly a gaussian-like. and we can approximate the observed variance as the squared-sigma of a gaussian fit.
, the observed distribution is mostly a gaussian-like. and we can approximate the observed variance as the squared-sigma of a gaussian fit. , the width of the time difference is
, the width of the time difference is ,
,

 .
.

 .
. ,
, is the pdf.
is the pdf. and variance
and variance 

 , it has relation with an independent variable
, it has relation with an independent variable  . We would like to know the relationship between
. We would like to know the relationship between  .
.


 .
.
 . Note that the mean and the peak of the chi-squared distribution is not the same that the peak at
. Note that the mean and the peak of the chi-squared distribution is not the same that the peak at  .
. ,
, is degree of freedom. In the cause of
is degree of freedom. In the cause of  , the
, the  , because there is 1 degree o freedom used in x. And because the 1 with the b is fixed, it provides no degree of freedom.
, because there is 1 degree o freedom used in x. And because the 1 with the b is fixed, it provides no degree of freedom.
