In this post, we discussed the Goodness of Fit for a simple regression problem.
In nuclear physics, the data we collected are plotted in histogram, and we have to fit the histogram to find the energies and resolutions. This is another class of problem for Goodness of Fit.
In general, depends on how we treat the data,
- treat it as a regression problem with error for each data follows Poisson distribution.
- treat it as a testing hypothesis that what is the chance for the experimental distribution be observed, given that the model distribution is truth?
For the regression problem, there are 2 mains metrics, one is the R-squared, and the another is the chi-squared.
For the testing hypothesis, the experimental data is tested against the null hypothesis, which is the model distribution. A common method is the Pearson’s chi-squared test.
Note that the chi-squared and chi-squared test are two different things, although they are very similar in the algorithm.
Another note is that, please keep in mind that there are many things not discussed in below, there are many details and assumptions behind.
The R-squared is very simple, the meaning is How good the model captures the data. In a standard ANOVA (Analysis of variance, can be imagine as the partition of the SSTotal ), we have


The SSRTotal is the sum of square of “residuals” against the mean value. i.e., If the data has no feature, no peak, the SSTotal will be minimum. SSTotal represents the “size” of the feature in the data. Larger the SSTotal, the data is more different from the mean values, and more feature-rich.
The SSR is the sum of square of residuals against the fitted function. If the model captures the data very well, SSR will be minimum. Since the data could have some natural fluctuation, the 


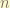 is the size of the data,
is the size of the data,  is the number of parameter of the model, or the size of the model. The SSTotal is the “size” of feature, SSR is the “size” of the things that did not captured by the model. The basic of ANOVA is the study of the partition of the data.
is the number of parameter of the model, or the size of the model. The SSTotal is the “size” of feature, SSR is the “size” of the things that did not captured by the model. The basic of ANOVA is the study of the partition of the data. The difference between SSTotal and SSR is the “size” of the model captured data.

The idea of R-squared is that, the numerator is the size that the model captured from the data, and the denominator is the size of the feature in the data. If the data is featureless, thus the data is mainly from the natural fluctuation, therefore, there is nothing a model can be captured. so, R-squared will be small.
Chi-squared includes the sample variance,

We can see that the 


For histogram data, the sample variance of each bin should follow the Poisson statistics that 
The reduced chi-squared is

For 


Pearson’s chi-squared test, is a testing, asking, does the data distribution can be captured by a model distribution, more technically, what is the probability to observed the experimental distribution, given that the model distribution is truth. One limitation for using this test is that, the number of data for each bin cannot be too small.
The test calculate the following quantity,

The 
As all testing hypothesis, we need to know the probability of the tail. For

The meaning of the p-value is that,
given the null hypothesis, or the model distribution, is truth, the probability of the experimental data happen.
When the p-value is less than 5%, the null hypothesis should be rejected. In other word, the model distribution cannot represents the experimental distribution. Or, if the model distribution is truth, less than 5% chance to observe the experimental data.



 is a m-dimensional data column vector,
is a m-dimensional data column vector,  is a n-dimensional parameter column vector, and
is a n-dimensional parameter column vector, and  is a n-m non-square matrix.
is a n-m non-square matrix. . when
. when  , it is not really a fitting because of degree-of-freedom is
, it is not really a fitting because of degree-of-freedom is  , so that the fitting error is infinity.
, so that the fitting error is infinity.


 is zero. Thus the expected parameter is
is zero. Thus the expected parameter is

 is the degree of freedom, which is the number of value that are free to vary. Many people will confuse by the “-1” issue. In fact, if you only want to calculate the sum of square of residual SSR, the degree of freedom is always
is the degree of freedom, which is the number of value that are free to vary. Many people will confuse by the “-1” issue. In fact, if you only want to calculate the sum of square of residual SSR, the degree of freedom is always  .
.
 is a bit out-side the sub-space. The linear regression is a method to find the shortest distance from
is a bit out-side the sub-space. The linear regression is a method to find the shortest distance from  .
. and variance
and variance 

 , it has relation with an independent variable
, it has relation with an independent variable  . We would like to know the relationship between
. We would like to know the relationship between  .
.


 .
.
 . Note that the mean and the peak of the chi-squared distribution is not the same that the peak at
. Note that the mean and the peak of the chi-squared distribution is not the same that the peak at  .
. ,
, , the
, the  , because there is 1 degree o freedom used in x. And because the 1 with the b is fixed, it provides no degree of freedom.
, because there is 1 degree o freedom used in x. And because the 1 with the b is fixed, it provides no degree of freedom. , which is caused by a charged particle executing orbital motion, since there are 3 dimension space. and spin
, which is caused by a charged particle executing orbital motion, since there are 3 dimension space. and spin 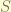 , which is an internal degree of freedom to let particle “orbiting” at there.
, which is an internal degree of freedom to let particle “orbiting” at there.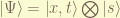

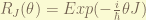
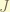 can be either
can be either 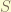 .
.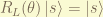
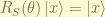
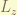 can only have integral value but
can only have integral value but  can be both half-integral and integral. the half-integral value of
can be both half-integral and integral. the half-integral value of  makes the spin-state have to rotate 2 cycles in order to be the same again.
makes the spin-state have to rotate 2 cycles in order to be the same again.

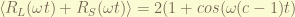
 and
and  is equal to
is equal to 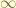 . the different in the c will come up at very long time measurement and it exhibit a interference pattern.
. the different in the c will come up at very long time measurement and it exhibit a interference pattern. is a complex number, it will cause a decay, and it will be reflected in the interference pattern.
is a complex number, it will cause a decay, and it will be reflected in the interference pattern.![[x,S]=0 ?](https://s0.wp.com/latex.php?latex=%5Bx%2CS%5D%3D0+%3F+&bg=fafad3&fg=6f5e4e&s=0&c=20201002)
![[p,S]=0 ?](https://s0.wp.com/latex.php?latex=%5Bp%2CS%5D%3D0+%3F+&bg=fafad3&fg=6f5e4e&s=0&c=20201002)
![[p_x, S_y] \ne 0 ?](https://s0.wp.com/latex.php?latex=%5Bp_x%2C+S_y%5D+%5Cne+0+%3F+&bg=fafad3&fg=6f5e4e&s=0&c=20201002)

![[V_i, J_j] = i \hbar V_k](https://s0.wp.com/latex.php?latex=%5BV_i%2C+J_j%5D+%3D+i+%5Chbar+V_k+&bg=fafad3&fg=6f5e4e&s=0&c=20201002) run in cyclic
run in cyclic
