There are many kind of wavelet transform, and I think the names are quite confusing.
For instance, there are continuous and discrete wavelet transforms, in which, the “continuous” and “discrete” are for the wavelet parameters, not for the “data” itself. Therefore, for discrete data, there are “continuous” and “discrete” wavelet transforms, and for function, there are also “continuous” and “discrete” wavelet transforms.
In here, we will focus on discrete wavelet transform for function first. This discrete wavelet transform is also called as wavelet series, which express a compact support function into series of wavelet.
For simplicity, we also focus on orthonormal wavelet.
As the wavelet span the entire space, any compact function can be expressed as


where 
Now, we move to discrete data discrete wavelet transform. The data is discrete, we can imagine only 
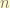

the integration becomes a finite sum.
Without loss of generality, we can set 



However, this double summation for each 
From the last post, we know that the scaling function that generate a MRA must be:


, where 



The set of shifted wavelet span a space 


Since the wavelet is generated from the scaling function, we expect the coefficient of 


For discrete data 

to decompose to the 





where (given that 



Therefore, using the coefficient of 




in graphic representation

This is a fast discrete wavelet transform.
Due to the nested space of MRA, we also expect that the coefficient 



Since the 
To reconstruct the discrete data 

using the nested space of MRA, 

in graphical representation,

I attached the wavelet transfrom class for Qt, feel free to modify.
https://drive.google.com/file/d/0BycN9tiDv9kmMVRfcVFMbDFWS0k/view?usp=sharing
https://drive.google.com/file/d/0BycN9tiDv9kmUmlmNk1kaVJCbEU/view?usp=sharing
in the code, the data did not transform to MRA space. The code treats the data already in the MRA space. Some people said this is a “crime”. But for the seek of “speed”, it is no need to map the original discrete data into MRA space. But i agree, for continuous function, we must map to MRA space.
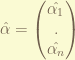 is the column vector of basis reference vector.
is the column vector of basis reference vector.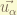 is the coordinate column vector in
is the coordinate column vector in 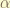 basis.
basis. is the vector in space
is the vector in space is the transformed vector in space.
is the transformed vector in space. and
and  are the matrix of transform.
are the matrix of transform. has the same meaning of
has the same meaning of 
 triangle just demonstrate how 2 steps frame transform can be reduced to the vector transform in same frame.
triangle just demonstrate how 2 steps frame transform can be reduced to the vector transform in same frame.
